|
Are you excited about AI but concerned about humanity losing control of it? Then please consider collaborating with our group! Our main focus is on mechanistic interpretability (MI): given a trained neural network that exhibits intelligent behavior, how can we figure out how it works, preferably automatically? Today's large language models and other powerful AI systems tend to be opaque black boxes, offering few guarantees that they will behave as desired. In order of increasing ambition level, here are our three motivations:
|
|
|

Max Tegmark PI Website / Twitter |

Ziming Liu PhD student Website / Twitter |

Eric J. Michaud PhD student Website / Twitter |

David D. Baek PhD student Website / Twitter |

Josh Engels PhD student Website / Twitter |

Subhash Kantamneni Master's student Twitter |
|
Below are examples of our Mechanistic Interpretability research so far, which includes auto-discovering knowledge representations, hidden symmetries, modularity and conserved quantities. You'll find a complete list of our publications here. |
|
Ziming Liu, Eric Gan, Max Tegmark arXiv / GitHub / Colab Demo To make neural networks more like brains, we embed neurons into a geometric space and maximize locality of neuron connections. The resulting networks demonstrate extreme sparsity and modularity, which makes mechanistic interpretability much easier. |
|
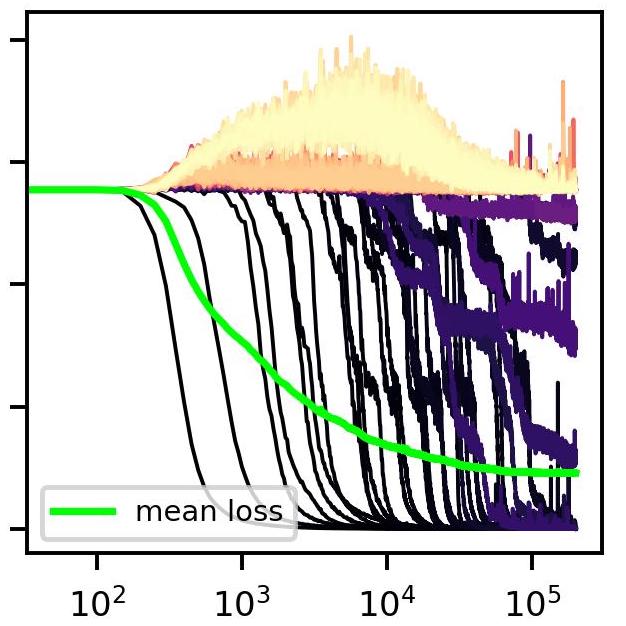
Eric J. Michaud, Ziming Liu, Uzay Girit, Max Tegmark arXiv / GitHub We develop a model of neural scaling laws where a Zipf distribution over discrete subtasks translates into power law scaling in the number of network parameters and the amount of training data. |
|
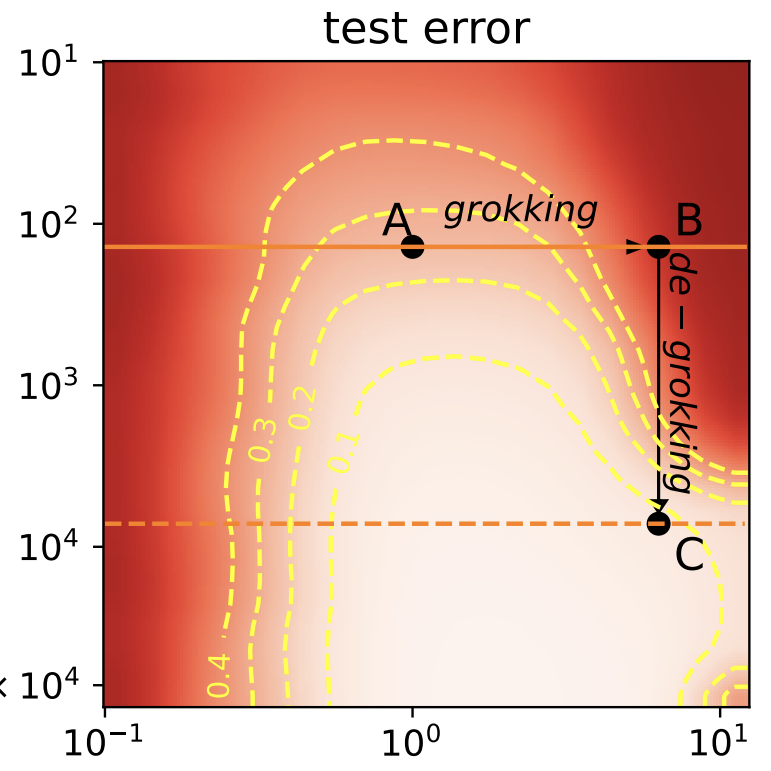
Ziming Liu, Eric J. Michaud, Max Tegmark ICLR 2023 (Spotlight) arXiv / GitHub We understand the phenomenon of "grokking" in neural networks in terms of the interplay between generalization and network weight norm, and use this understanding to control grokking: we can induce grokking (delay generalization) in a wide range of tasks and reduce grokking (accelerate generalization) on algorithmic tasks. |
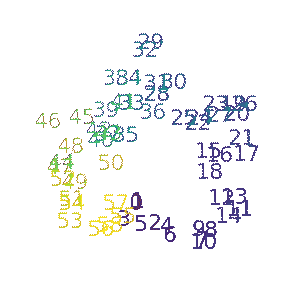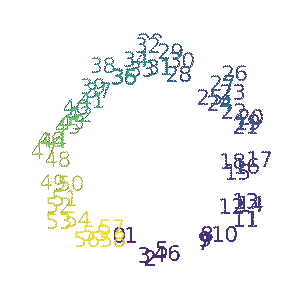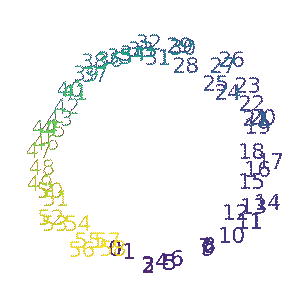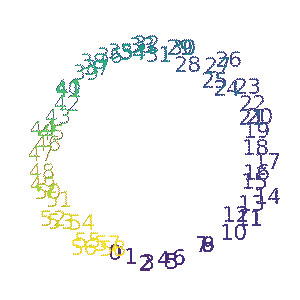
|
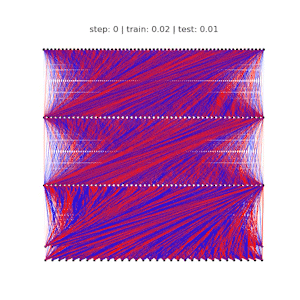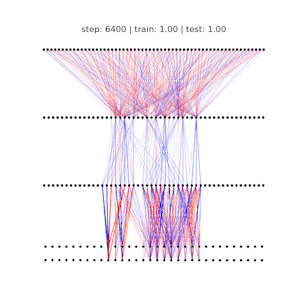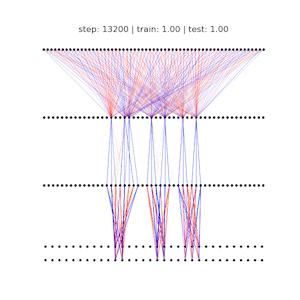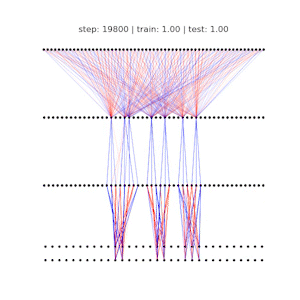
Ziming Liu, Ouail Kitouni, Niklas Nolte, Eric J. Michaud, Max Tegmark, Mike Williams ICLR 2023 (Spotlight) arXiv / GitHub We study the relationship between generalization and the formation of structured representations in neural networks trained on algorithmic tasks. |